
문제
그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
입력
첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
출력
첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
예제 입력 1
4 5 1
1 2
1 3
1 4
2 4
3 4
예제 출력 1
1 2 4 3
1 2 3 4
예제 입력 2
5 5 3
5 4
5 2
1 2
3 4
3 1
예제 출력 2
3 1 2 5 4
3 1 4 2 5
예제 입력 3
1000 1 1000
999 1000
예제 출력 3
1000 999
1000 999
일단 이 문제를 보면 그래프를 포현할 줄 알아야 합니다.
보통 통째로 인접행렬을 주는 것이 아니라 쌍으로 주는 경우 백터를 이용해 인접리스트로 많이 사용합니다.
C++ STL <vector>을 include하면 벡터를 쓸 수 있습니다.(벡터가 무엇인지는 뒤에 설명합니다)
문제에 DFS와 BFS가 언급이 되는데,
DFS는 Depth First Search의 약자로 깊이우선탐색,
BFS는 Breath First Search의 약자로 너비우선탐색을 의미합니다.
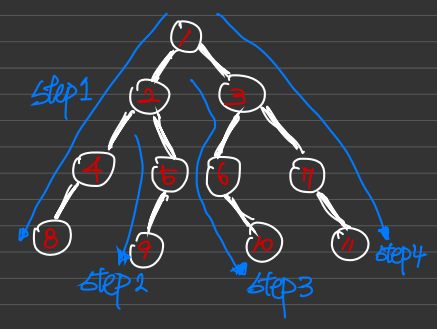
DFS는 기본적으로 스택을 주로 사용합니다. 그 이유는 1을 방문하면 번호가 낮은 노드를 우선 방문한다 했을때 2 - 4 - 8순으로 들어가게 되는데 이때 인접한 노드가 없으면 돌아가야하는 순서가 8 - 4 이런식으로 됩니다. 이때 스택을 사용하면 노드를 방문할때는 원소를 넣고 돌아갈때는 원소를 빼는 방식으로 노드를 순회할 수 있기 때문입니다.
위의 허접한 그림으로 설명하자면 일단 방문한 노드를 체크하는 배열을 만듭니다. ( bool visited[12]을 전역으로 선언 )
스택을 만들고 원소 1을 넣고 visited[1]=true, 1과 인접한 노드중 값이 작은 2를 스택에 넣어주고 visited[2]=true. 2와 인접한 4 5중 4를 넣고 visited[4]=true, 4와 유일하게 인접하는 8 원소를 넣고난 후에 다시 visited[8]=true, 연결된 노드가 없으므로 8을 빼주고 4를 빼줍니다. 그렇게 되면 다시 2로 돌아오는데 이때 5- 9..이런식으로 다음 노드도 순회하게 됩니다.

BFS는 기본적으로 큐를 주로 사용합니다. 그 이유는 1과 인접한 2 3을 방문하고 2와 인접한 4 5 ,3과 인접한 6 7 을 방문할때, 1과 인접한 노드 2 3을 큐에 넣어주고 2와 인접한 노드를 4 5를 큐에 넣어주면 위 그림의 번호대로 노드를 방문할 수 있게 됩니다. 큐의 들어있는 원소를 나타내면
1
2 3
4 5 6 7이런식으로 dequeue하는 순서는 1-> 2-> 3-> 4순이기 때문에 큐를 사용하는 것이 편하다 할 수 있겠습니다.
스택은 #include<stack>을 해주면 라이브러리를 사용할 수 있고,
stack<자료형> s(s는 변수명)으로 선언 할 수 있습니다.

큐는 스택과 마찬가지로 #include<queue>를 하여 사용할 수 있고,
queue<자료형> q(q는 변수명)으로 선언 할 수 있습니다.

마지막으로 벡터를 사용하여 그래프를 구현하였는데 벡터(vector)는 동적 배열이라고 생각하시면 됩니다.
흔히 배열을 선언하면 배열의 크기가 정해져 있기 때문에 원소를 적게쓰면 메모리가 낭비되고 원소를 더 쓰고싶을때
가득 차 있으면 불편한 상황이 일어나게 되는데 이때 벡터를 사용하게 되면 원소를 자유롭게 넣었다 뺏다 할 수 있게 됩니다.
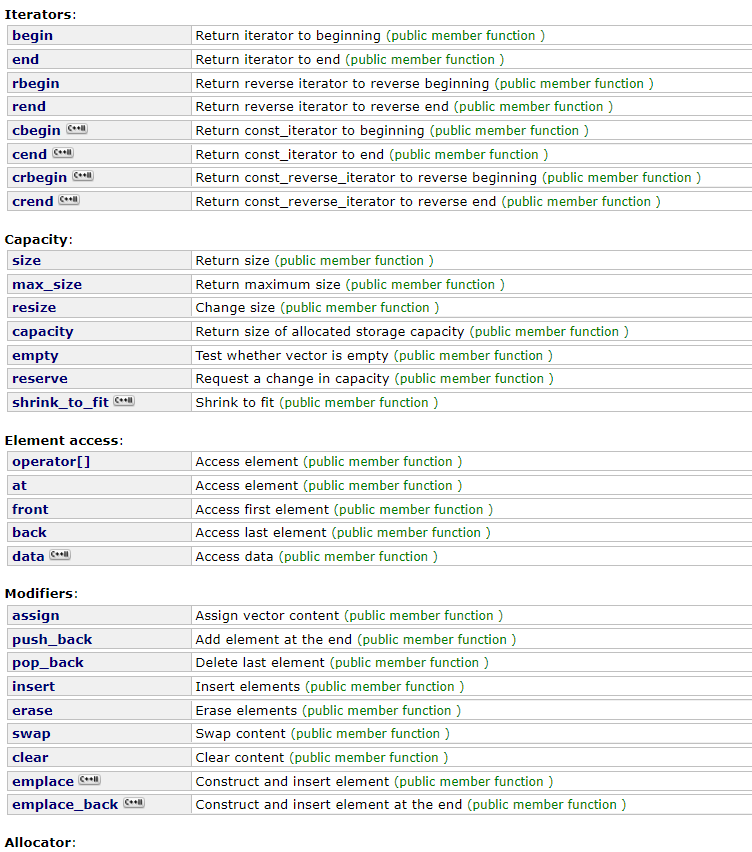
벡터의 경우 많이 쓰이기도 하고 함수도 많기 때문에 관련 레퍼런스를 참조하시는 것을 추천드립니다
www.cplusplus.com/reference/vector/vector/?kw=vector
vector - C++ Reference
difference_typea signed integral type, identical to: iterator_traits ::difference_type usually the same as ptrdiff_t
www.cplusplus.com
#include<iostream>
#include<vector>
#include<queue>
#include<algorithm>
#define MAX 1001
bool visited[MAX];
using namespace std;
vector<int> adj[MAX];
void dfs(int s){
if(visited[s-1])
return;
visited[s-1]=true;
cout<<s<<" ";
for(auto u: adj[s])
dfs(u);
}
void bfs(int x){
queue<int> q;
for(int i=0;i<MAX;i++)
visited[i]=false;
int distance[MAX]={0,};
visited[x]=true; distance[x]=0;
q.push(x);
cout<<x<<" ";
while(!q.empty()){
int s=q.front(); q.pop();
for(auto u: adj[s]){
if(visited[u]) continue;
visited[u]=true;
cout<<u<<" ";
distance[u]=distance[u]+1;
q.push(u);
}
}
}
int main(){
int N,M,V;
cin>>N>>M>>V;
for(int i=0;i<M;i++){
int num1,num2;
cin>>num1>>num2;
adj[num1].push_back(num2);
adj[num2].push_back(num1);
}
for(int i=0;i<N;i++)
sort(adj[i].begin(),adj[i].end());
dfs(V);
cout<<'\n';
bfs(V);
}
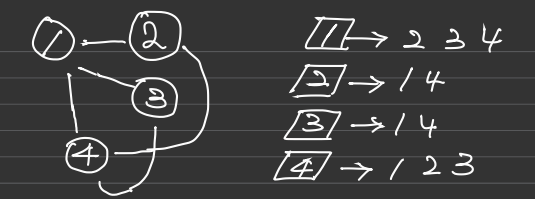
벡터 배열을 만들고 원소를 넣은 후 노드번호가 가장 작은 것부터 방문한다 하였으므로 <algorithm>헤더파일의 sort함수를 사용하여 정렬하였습니다.
'알고리즘 > 백준 BOJ 문제풀이' 카테고리의 다른 글
| 백준 1748 : 수 이어쓰기 1 (C++) (0) | 2021.03.09 |
|---|---|
| 백준 1068 : 트리 (C++) (0) | 2021.03.08 |
| 백준 2178 : 미로 탐색 (C++) (0) | 2021.03.04 |
| 백준 1978 : 소수찾기 (C++) (소수판별 알고리즘) (0) | 2021.03.01 |
| 백준 1003 : 피보나치 함수 (C++) (0) | 2021.03.01 |